
核心结论:从“人写代码”到“人管AI写代码”
OpenClaw是一个开源的AI Agent框架,通过自然语言与AI协作完成复杂的编程任务。它的本质是把开发者从“执行者”变成“指挥官”。

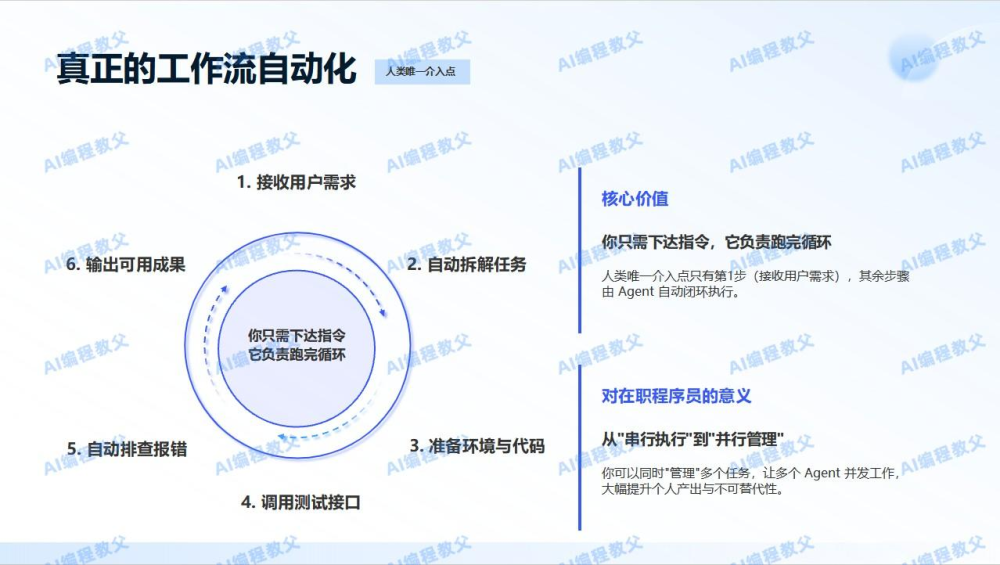
一、团队落地AI编程的四步路线图
Step 1:服务器选型
推荐配置:2核4G起步,海外节点(硅谷/新加坡)

为什么不用本地电脑?
- 网络环境复杂,API调用经常超时
- 电脑关机,数字员工就下班
- AI自动执行脚本可能误删本地文件
国内vs海外服务器: 海外节点直连大模型API,网络稳定,无需代理。国内服务器调用海外API需要配置复杂代理,极易超时断连。
Step 2:模型配置
核心认知:工具是枪,模型是子弹。
通过红烁API中转站接入海外顶级模型:

为什么推荐中转站而非官方直连?

场景化模型选型建议:

Step 3:接入飞书机器人
为什么选飞书?
- 多端实时同步,手机/电脑/平板随时随地查看进度
- 原生支持Markdown渲染、代码高亮显示
- 可拉入项目群聊,团队一起看AI写代码
配置要点(90%新手踩坑):
- 事件订阅必须选择WebSocket模式,无需公网IP,无需内网穿透
- 配置openclaw.json时,mode务必设为"websocket"
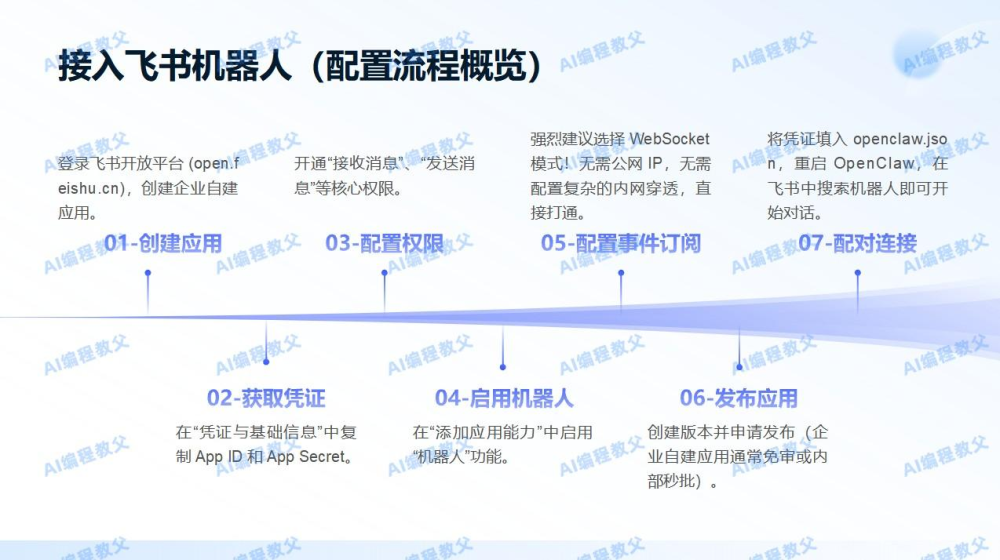
Step 4:验证最小可用路径

在飞书中搜索机器人,发送“你好”,收到回复即代表全链路跑通。
二、OpenClaw核心组件解析
目录结构

核心认知: openclaw.json是给“系统”看的(底层驱动);workspace里的.md文件是给“大模型”看的(Prompt上下文)。
SOUL.md:定义代码规范

规则越具体、越符合团队实际情况,Agent产出的代码质量就越高。
MEMORY.md:长期记忆机制
Agent会记住核心决策、个人上下文、提炼的知识、全局约定。
实战铁律: 永远不要依赖Agent的“口头答应”。如果想让它记住,必须明确要求它写入文件。
HEARTBEAT.md:主动性引擎
这是OpenClaw与其他工具的本质区别——Agent可以定期“醒来”主动干活。

三、多Agent协作:按业务域划分,不要按职能划分
错误做法:按职能划分
产品经理Agent → 前端Agent → 后端Agent
- 沟通成本极高,上下文在传递中不断丢失
- 前端不知道后端逻辑,后端不理解产品初衷
正确做法:按业务域划分
- 项目A全栈Agent(独立Workspace)
- 项目B全栈Agent(独立Workspace)
- 数据分析Agent(独立Workspace)
每个Agent拥有独立的记忆和工作区,掌握该业务的完整上下文。
多Agent配置(openclaw.json)

核心铁律: 不要拉群让多个Agent“开会”。群聊中每个Agent维护独立的Session,无法共享上下文,会导致指令冲突和资源抢占。正确方式是主Agent通过session_send私聊调度子Agent。
四、经济账:为什么用顶级模型反而更省钱
设定场景: 资深开发工程师,月薪20,000元;复杂遗留系统重构与深层Bug修复

单次任务立省¥2,605。API费用远小于人力成本。
核心认知:算力比人力便宜。核心业务果断使用顶级模型,拒绝无效内耗。
五、团队落地效果
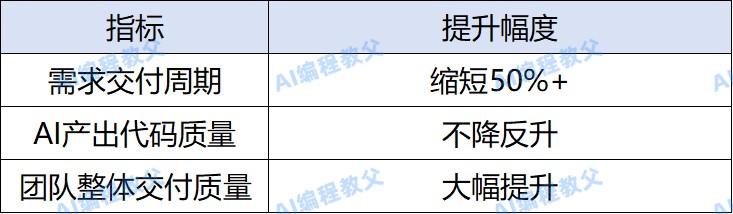
后端工程师反馈: 把接口文档喂给Agent,自动生成基础代码和单元测试。只专注核心业务逻辑和架构设计,准点下班。
技术负责人反馈: Agent接入CI/CD流程,自动完成代码初筛和Bug定位。有精力规划技术演进,不再每天救火。
六、快速诊断表:90%的问题先看这里

飞书机器人不回复排查顺序:
- 网关是否正常运行?
- 模型的API Key / Base URL对不对?
- 飞书应用配置对不对?
- 事件配置/长连接有没有保存成功?
- 日志里到底报了什么错?
七、核心认知总结

第一性原理: 万事问AI。遇到任何概念、报错或思路卡壳,第一反应应该是向AI提问。
真正的执行力: 不是“照做教程”,而是“遇到问题想方设法解决”。遇到卡壳,先加日志、先写Demo、先问AI,不要停下来等答案。
评论区聊聊:你给第一个Agent是按业务域划分还是按职能划分?有没有试过把多个Agent拉群开会结果翻车?留言说说你的“数字员工”管理心得。
继续看红烁AI的落地方案
如果你正在把文中的方法落到团队里,可以继续看对应的商业方案页。